電子書籍をオーディオブックに変換するうえで Block ベースのアーキテクチャが重要な理由
目次
序章
オーディオブックの普及は、読者や学習者が本から情報を得る方法を劇的に変化させ、比類のない利便性を提供し、新しい読者層に届くようになりました。しかし、数十万文字に及ぶ電子書籍を、流暢かつ自然なオーディオブック音声に変換することは、単にテキストをTTSエンジンに入力するほど簡単なものではありません。

BookFabの使命は、大規模な電子書籍コンテンツと高品質な音声制作との間のギャップを埋めることであり、プロセスのすべての段階を信頼性、効率性、操作性に最適化することです。その仕組みの中心であるのが、Blockという概念です。Blockは、柔軟かつ知的に設計された処理単位、テキスト構造解析と最新のTTSワークフローの強みを組み合わせています。
なぜ直接文や段落を生成しないのか?どうすれば文脈の自然さを保ったまま、何百もの章を同時に生成できるのか?その答えはBlockベースの仕組みにあります。本記事では、その仕組みを詳しくご紹介します。
テキスト処理の構造
電子書籍を高品質な音声に変換するには、単なる文字から音声への変換だけでは十分ではありません。特に数千ページ規模になると、構造、文脈、ワークフローを考慮した丁寧なアプローチが欠かせません。では、BookFabはどのように複雑な電子書籍を、意味と流れを維持したまま、音声化に適した形式へ分解しているのでしょうか?
ここで、自動オーディオブック生成を堅牢かつ信頼性の高いものにしている多層的なプロセスを詳しく見ていきます。
章と段落の処理
オーディオブック合成を開始する前に、BookFabはまず電子書籍の構造階層を解析します。各ファイルは章、小章、標準的な段落を区別するように解析され、それぞれがオーディオ出力の流れと一貫性を導く重要な役割を担っています。
章や段落を正確に検出することは、電子書籍を高品質なオーディオブックへ変換する上で不可欠です。これにより、ナラティブのペース、文脈、論理的な区切りが合成過程において保持されます。
BookFabは言語認識に対応した解析アルゴリズムを使用しています。標準的な小説では、章タイトルや番号、特有のフォーマットマーカーなどを用いてテキストを分割します。章内ではさらに段落単位に分割すると同時に、節区切り・引用・リストといった埋め込まれたメタデータも解析します。この多層的解析は自然なポーズやイントネーションを導くと同時に、次の処理段階であるBlock生成の基盤として機能します。
長い章をそのままTTSに投入した経験がある方ならおわかりの通り、段落マーカーを失われると、音声は単調かつ機械的になります。BookFabはこれらのテキスト境界を遵守することで、自然で理解しやすいリスニング体験を保証しています。
私自身も同様の経験をしており、ほんのわずかな構造の見落としで物語の流れが壊れてしまうと、それは単なる技術的な問題にとどまらず、聴く楽しみそのものを損なってしまいます。
なぜBlockが重要なのか
電子書籍を逐文あるいは逐段落で処理すればよいのではないか、と考える方もいるかもしれません。しかし、この方法は一見単純であるものの、単位が小さすぎれば不自然な音声や不格好な間が生じ、大きすぎればTTSの入力上限を超えてしまい、文脈の一貫性が損なわれます。
こうした問題を解消するために考案されたのがBlockという概念です。文脈と効率性の均衡を取ることを目的としています。
Blockとは、論理的に関連する複数の文をまとめた柔軟な単位であり、段落をまたいでまとめられることはあるが、文中で切られることはない。各Blockは、利用するTTSサービスごとの文字数・バイト数制約を超えないように調整されつつ、自然なナレーションに必要な文脈を十分に保持しています。
両極端の手法を試行した結果、多くのチームは、逐文レベルの細分化も過大なセグメントも、技術的要件とリスニングニーズを同時に満たすことはできないと理解するようになりました。Blockを活用することで、BookFabはリクエスト数の最適化、エラー処理の効率化、音声一貫性の向上を実現しつつ、自然な流れとより豊かなユーザー体験を確保することが可能になります。
BookFab Blockワークフロー
BookFabのBlockベースのワークフローは、電子書籍の長さや複雑さを問わず、オーディオブック自動化を効率化するよう設計されています。実際の一連のプロセスは次のようになります。
- 階層ごとの解析:システムは電子書籍を章および段落に分解し、書式情報および構造的手掛かりをすべて取得します
- Blockを作成:文をBlock単位に集約し、各Blockが言語固有の文字数・バイト数制約を超えないよう管理します。文の途中で分割されることはありません。
- 分散処理:Blockを複数のTTSエンジンへ並列的に送信します。この処理により合成の高速化と分散サーバー資源の最大活用が実現されます。
- 結果統合:章内のすべてのBlock音声が生成され次第、BookFabはそれらをBlock順に統合し、シームレスな章単位の音声ファイルを構築します。後にBlockが更新された場合、そのBlockのみを再生成すれば足り、章全体を再処理する必要はありません。
要点まとめ:
- Blockは初回生成だけでなく将来の更新にも再利用可能な最小単位です。
- Blockの並列処理によって、長編書籍でも大幅な時間短縮が可能です。
- 細かなBlock管理により、エラー処理、バージョン管理、品質保証が容易になります。
数百に及ぶ音声断片の統合や大規模ファイルの再処理に伴う負担は珍しくない。BookFabの構造化されたワークフローはその煩雑さを軽減し、制作者が高品質なコンテンツ提供に注力できる環境を整える。
Block分割の原則
長大な電子書籍を高品質なオーディオブックに変換するには、単に文字を音声に変換するだけではなく、音声合成のためにどこでテキストを「分割する」かを正確に判断することが重要です。
不適切な分割は、ナラティブの流れを妨げ、技術的な不具合を引き起こし、将来的な更新作業を複雑化させる。BookFabはこうした課題に対応するために、言語の違いや運用上のベストプラクティスを踏まえた、明確かつ製品志向のBlock作成ルールを採用しています。
言語別の文字数制限
BookFabは、単なる理論的API最大値に依拠するのではなく、実際の運用経験に基づいて厳格なBlockサイズ基準を定めています。これにより技術的堅牢性と自然なリスニング体験が保証されます。
デフォルトでは、BookFabにおける各Blockは、英語で9,000文字、日本語で3,000文字を上限としています。
これらの設定は厳密なテストに基づいており、過負荷エラーを防ぎ、合成処理を安定して応答させ、変換全体を通して高品質な音声を維持するために設計されています。
なぜこのような差があるのでしょうか。英語のBlockは、よりコンパクトなエンコードと単純な言語構造を持つため、大きく設定することが可能です。一方、日本語はマルチバイト文字を使用するため、パフォーマンスを最適化し、メモリを安全に保つには小さな単位での分割が必要となります。
混合言語の書籍や新しいTTSの利用場面では、必要に応じてこれらのBlock制限を調整できますが、デフォルト値であってもほとんどのプロジェクトで十分な安定性が確保されます。
文の完全性を保持する
技術的な制約は、リスニング体験を損なわない限りで初めて意味を持ちます。そのためBookFabでは、「Blockが文を分割してはならない」という厳格なルールを採用しています。
もし1文を追加することでBlockサイズの上限を超える場合、その文全体を次のBlockへ送ります。文を途中で切ることは絶対にありません。
この方法は一見すると当然のように思えますが、大規模な自動処理においては非常に重要です。文を途中で分割すると、不自然な音声や不自然なポーズが生じたり、TTSエンジンが断片的なデータを想定していない場合には合成エラーを引き起こす可能性があります。各Blockに文全体を保持することで、BookFabはナレーションの流れと意味の明瞭さを維持します。
章の境界制限
BookFabでは、Blockが章の境界を越えることを禁止しています。実際には、長い章の最後のBlockは標準サイズより小さくなる場合がありますが、それでも必ずその章のテキストだけを含みます。
例:日本語の章が7,500文字の場合
• Block 1: 3,000文字
• Block 2: 3,000文字
• Block 3: 1,500文字
最後のBlockがどれほど小さくても、次章のコンテンツと統合されることはありません。このルールにより、音声ファイルは章単位で一貫して整理され(1章=1ファイル)、更新作業も大幅に簡素化されます。1章内の変更が次章に影響することはありません。
Blockの統合と更新
各Blockが処理され音声ファイルへ変換された後も、作業は終わりではありません。スムーズでユーザーフレンドリーなオーディオブックを実現するためには、それらのセグメントを正確に結合し、修正が必要な際には効率的に更新できる仕組みが不可欠です。BookFabの統合・更新戦略は、最終的なリスニング体験を一貫性・保守性の高いものとし、そして大規模制作にも柔軟に対応可能なものとしています。
章単位の音声ファイル生成
ある章に含まれるすべてのBlockが合成されると、BookFabはそれらを自動的に順序通りに統合します。各Blockの音声は隙間や重なりなく結合され、単一で連続した章レベルの音声ファイルになります。
この方法によって、テキストに記されたテンポや切り替え、ポーズが忠実に再現され、リスナーにシームレスで物語に没入できる体験を提供します。
章ごとに音声をまとめることで、BookFabはナビゲーション・再生・配信を簡素化し、利用者が一度に通して聴く場合にも、特定の箇所を聴き直す場合にも対応しやすくなります。
効率的なBlock再生成
Block単位での処理には、オーディオブックの一部だけを効率的に更新できるという利点があります。章や書籍全体を再生成する必要はありません。
発音の修正や、特定の場面で別の声に差し替える場合でも、該当するBlockのみを再生成すれば対応可能です。
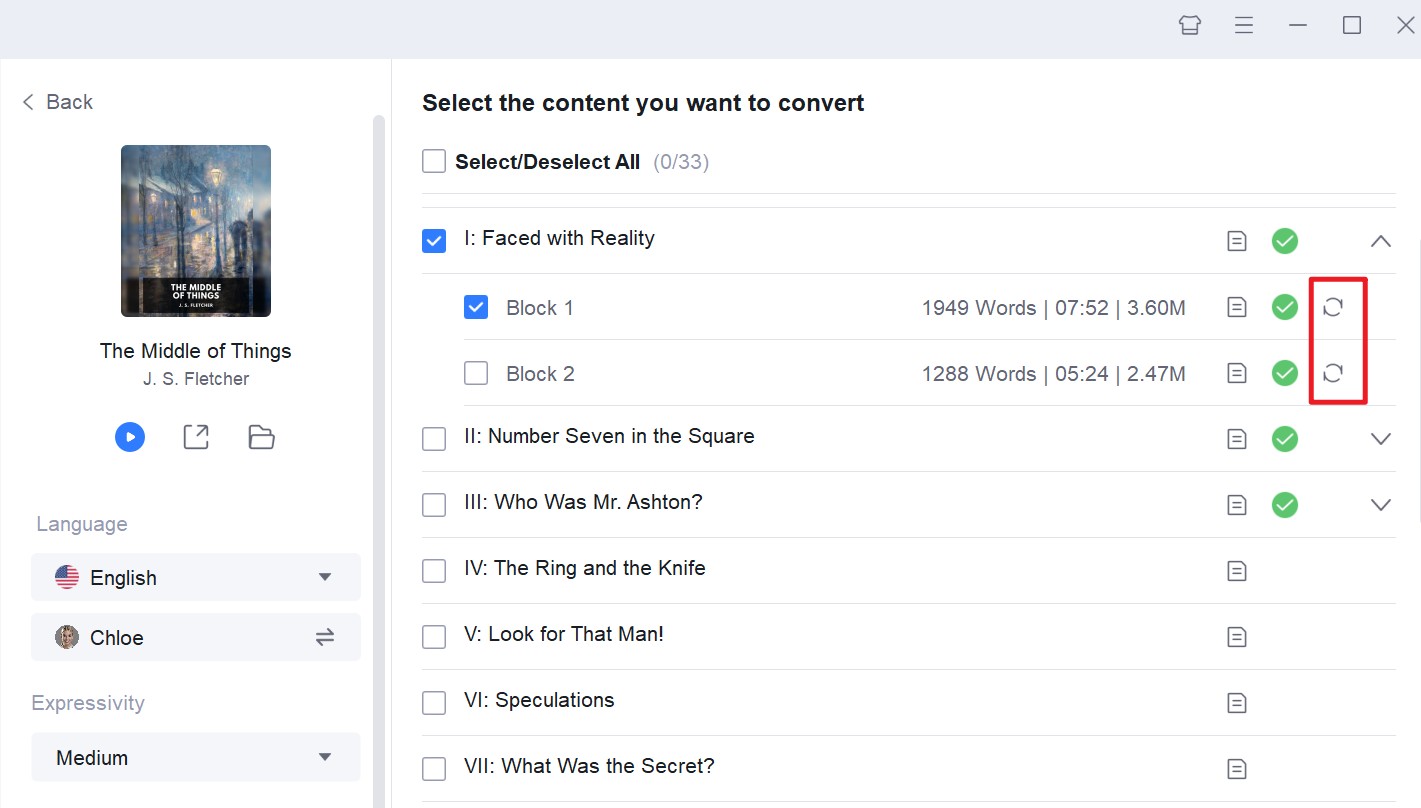
BookFabの処理手順:
• 章内の古いBlock音声を新しい音声に差し替える
• 章全体を素早く再結合し、新しいオーディオファイルとして生成する
• 関連するJSONインデックスデータを更新し、再生プレイヤーや配信プラットフォームが常に最新の音声を参照できるようにする
この仕組みにより、誤りの修正や改善の反映が迅速かつ確実に行われ、章単位や書籍全体を再処理する場合に比べて作業負担を大幅に削減できます。
Block設計の利点
BookFabにおけるBlockベースの設計思想は、単なる技術的選択ではなく、効率性・音質・運用の柔軟性を引き出す戦略的な判断です。以下では、Block管理によって大規模なオーディオブック生成がどのように効率的で拡張可能なワークフローへと変わるのかを説明します。
速度と並列処理
コンテンツを個別のBlockに分割することで、BookFabは真の並列処理を可能にしています。実際の運用では、同時に最大3つのBlockを並列処理ができ、大規模で複雑な書籍であっても生成速度を大幅に向上させます。
章や書籍全体の処理が順番に終わるのを待つのではなく、システムは3つずつのBlockをTTSエンジンに配分します。ひとつの処理が終わればすぐに次が投入され、リソースの利用効率が最大化されます。
このアーキテクチャにより、処理時間全体が短縮され、ワークフローのボトルネックが回避され、フルサイズのオーディオブックでも単一処理方式よりはるかに効率的に生成することが可能になります。
文脈の一貫性向上
単純に文単位で音声合成すると、音声が断片的かつ不連続となる重大な欠点があります。BookFabのBlockはこの問題を回避するために調整されており、短すぎて文脈を失うことも、長すぎてシステム制約を超えることもありません。
各Blockには十分な文脈が含まれているため、TTSエンジンは文や段落をまたいでも自然な抑揚と一貫した表現を維持できます。このバランスによってリスナーの体験は大きく向上し、切り替えは滑らかで、物語はBlockからBlockへと途切れることなく流れていきます。
結論と今後の展望
BookFabは、知的な中間レイヤーとしてBlockを導入することで、電子書籍をオーディオブックに変換するプロセスを革新しました。これにより、大規模な変換がより迅速に、より信頼性高く、そして管理しやすいものになっています。Blockの設計原則は、技術的な安定性だけでなく、シームレスな結合や素早い部分的更新を伴った高品質なリスニング体験も保証します。
将来に向けて、BookFabのBlockシステムはさらに進化を続けます。動的なBlockサイズや複数の声・オーディオトラック対応といった機能が予定されており、さらなる柔軟性と豊かなユーザー体験をもたらすでしょう。拡大を続けるオーディオブック業界において、BookFabは革新性、拡張性、そしてクリエイターに優しいツールを提供することで、業界でリーダーシップを発揮し続けるでしょう。



